| 如何进行分布表及分区裁剪 | 您所在的位置:网站首页 › split partition › 如何进行分布表及分区裁剪 |
如何进行分布表及分区裁剪
|
分布表使用 AnalyticDB PostgreSQL支持的分区表类型包括范围(Range)分区、值(List)分区和多级分区表,下图为一个多级分区表设计实例,一级分区采用按月的区间(Range)分区,二级分区采用按地区的值(List)分区设计。 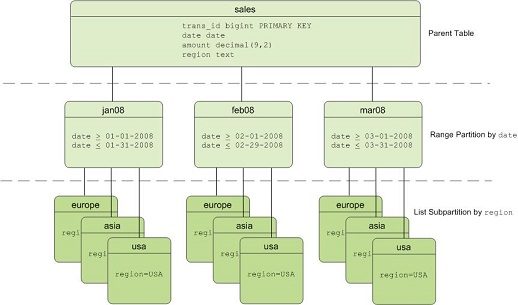 使用场景 使用场景是否使用分区表,可以通过以下几个方面进行考虑: 表数据量是否足够大:通常对于大的事实表,比如数据量有几千万或者过亿,可以考虑使用分区表,但数据量大小并没有一个绝对的标准可以使用,一般是根据经验,以及对目前性能是否满意。 表是否有合适的分区字段:如果数据量足够大了,这个时候需要看下是否有合适的字段能够用来分区,通常如果数据有时间维度,比如按天,按月等,是比较理想的分区字段。 表内数据是否具有生命周期:通常数仓中的数据不可能一直存放,一般都会有一定的生命周期,比如最近一年等,这里就涉及到对旧数据的管理,如果有分区表,就很容易删除旧的数据。 查询语句中是否含有分区字段:如果对一个表做了分区,但是所有的查询都不带分区字段,这不仅无法提高性能反而会使性能下降,因为所有的查询都会扫描所有的分区表。 创建范围(RANGE)分区表您可以通过给出一个START值、一个END值以及一个定义分区增量值的子句让数据库自动产生分区。默认情况下,START值总是被包括在内而END值总是被排除在外,例如: CREATE TABLE sales (id int, date date, amt decimal(10,2)) DISTRIBUTED BY (id) PARTITION BY RANGE (date) ( START (date '2016-01-01') INCLUSIVE END (date '2017-01-01') EXCLUSIVE EVERY (INTERVAL '1 day') );也可以创建一个按数字范围分区的表,使用单个数字数据类型列作为分区键列,例如: CREATE TABLE rank (id int, rank int, year int, gender char(1), count int) DISTRIBUTED BY (id) PARTITION BY RANGE (year) ( START (2006) END (2016) EVERY (1), DEFAULT PARTITION extra ); 创建值(LIST)分区表一个按列表分区的表可以使用任意允许等值比较的数据类型列作为它的分区键列。对于列表分区,您必须为每一个用户想要创建的分区(列表值)声明一个分区说明,例如: CREATE TABLE rank (id int, rank int, year int, gender char(1), count int ) DISTRIBUTED BY (id) PARTITION BY LIST (gender) ( PARTITION girls VALUES ('F'), PARTITION boys VALUES ('M'), DEFAULT PARTITION other );创建多级分区表支持创建多级的分区表。下述建表语句创建了具有三级表分区的表。一级分区在month字段上做RANGE分区,二级分区在region上做了LIST分区。 CREATE TABLE sales (id int, year int, month int, day int, region text) DISTRIBUTED BY (id) PARTITION BY RANGE (month) SUBPARTITION BY LIST (region) SUBPARTITION TEMPLATE ( SUBPARTITION usa VALUES ('usa'), SUBPARTITION europe VALUES ('europe'), SUBPARTITION asia VALUES ('asia'), DEFAULT SUBPARTITION other_regions) (START (1) END (13) EVERY (1), DEFAULT PARTITION other_months );分区表查询优化分区粒度 通常分区表的定义都涉及到粒度问题,比如按时间分区,究竟是按天,按周,按月等。粒度越细,每张表的数据就越少,但是分区的数量就越多,反之亦然。关于分区的数量,没有绝对的标准,一般分区的数量在200左右已经算是比较多了。分区表数目过多,会有多方面的影响,比如查询优化器生成执行计划较慢,同时很多维护工作也会变慢,比如VACUUM等。 对于多级分区表来说,分区文件的数量可能会增长得非常快。例如,如果一个表被按照月和城市划分并且有24个月以及100个城市,那么表分区的总数就是2400。特别对于列存表,会把每一列存在一个物理表中,因此如果这个表有100个列,系统就需要为该表管理十多万个文件。因此,在分区表设计之初首先需要考虑未来分区的总数,进而选择合理的分区定义。 分区裁剪 云原生数据仓库AnalyticDB PostgreSQL版支持分区表的分区裁剪功能。详细信息,请参见分区裁剪。 分区表维护分区表支持多种分区管理操作,包括新增分区,删除分区,重命名分区,清空分区,交换分区,分裂分区等,下面举例说明主要操作。 新增分区 如果存在default partition,则不能新增分区,只能split default partition。 ALTER TABLE test_partition_range ADD partition p2 start ('2017-02-01') end ('2017-02-28');删除分区 ALTER TABLE test_partition_range DROP partition p2;重命名分区 ALTER TABLE test_partition_range RENAME PARTITION p2 TO Feb17;清空分区 ALTER TABLE test_range_partition TRUNCATE PARTITION p1;交换分区 ALTER TABLE test_range_partition EXCHANGE PARTITION p2 WITH TABLE {cos_table_name} ;分裂分区 -- 将分区p2 在 '2017-02-20' 左右切分成两块 ALTER TABLE test_partition_range SPLIT partition p2 at ('2017-02-20') into (partition p2, partition p3); |
【本文地址】